
Implementierung einer Datenstrategie
Das Vorgehensmodell des Projekts Datenqualitätsstrategie hat nun die dritte Phase erreicht. Was alles in der Zwischenzeit passiert ist und warum es nicht mehr als “NUDAQ” bezeichnet wird, könnt ihr in diesem Artikel nachlesen.
Neues Akronym
Eines der ersten Ergebnisse der Pilotierung des NuDaK – Vorgehensmodell ist die Namensänderung. Das ist zwar nicht entscheidend für das strategische Vorgehen bei der inhaltlichen Implementierung, beruhigt aber, wenn auch das Akronym stimmig erscheint. Deshalb hier ein kurzer Ausflug, warum es überhaupt ein Akronym braucht. Ein Akronym bietet eine leicht zu merkende Möglichkeit etwas Komplexeres zu repräsentieren und fördert das gemeinsame Verständnis in der Kommunikation. NuDaK bedeutet Nursing Data Knowledge und steht im Gesamten dafür, wie man im Rahmen einer strategischen Vorgehensweise bei der Sekundärnutzung von klinischen Routinedaten Wissen für die Pflege generieren kann.
Datenmodellierung und Adaptierung
Nach Abschluss von Phase 2 „Datenset und Spezifikation“ (siehe Ausführung im Beitrag zu Phase 2) war es nun wichtig, die Erkenntnisse aus der Analyse der Dokumentationsprozesse und die Anforderungen aus dem Datenset in Phase 3 zusammenzuführen.
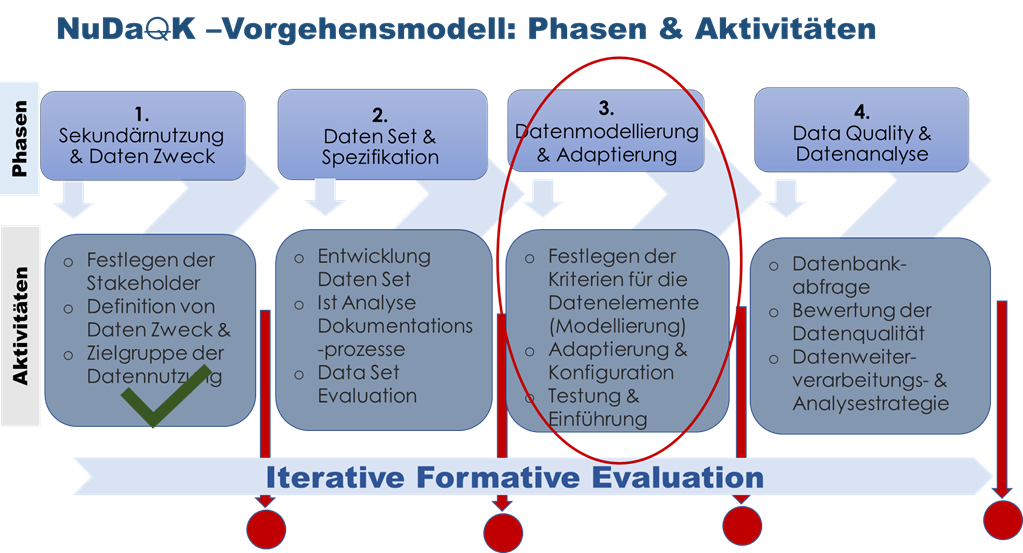
NuDaK – Vorgehensmodell (aktuelle Version_ 04_2024)
In einem ersten Schritt wurde ein sogenanntes „Informationsmodell“ entwickelt. Ein Informationsmodell ist eine strukturierte Darstellung von Informationen und hilft ein gemeinsames Verständnis zwischen IT und AnwenderInnen über die Daten zu bekommen. Ein Informationsmodell beschreibt in der Regel die Datenobjekte und ihre Merkmale und wie diese in Beziehung stehen. So können alle Beteiligten ein gemeinsames Verständnis drüber entwickeln, wie die Daten gespeichert, verwaltet oder genutzt werden sollen.
Im Rahmen dieses Projektes wurden alle Datenobjekte und Merkmale, aus dem Datenset „Schmerz“ im Informationsmodell beschrieben. Die Idee war, das Informationsmodell auf zwei Wege zu gestalten. In Phase 3 wurden zunächst alle Datenobjekte, die sich aus dem Datenset und nach der Analyse der Dokumentation ergaben, beschrieben. Im Weiteren wurden all jene Datenobjekte aufgegriffen, von denen ersichtlich war, dass diese im Rahmen der Dokumentation kaum standardisiert waren bzw. relevante Datenobjekte fehlten.
Gemeinsam mit den PflegeexpertInnen aus der Praxis der Barmherzigen Brüder Salzburg und der Fa. Care Solutions wurde anschließend überlegt, wie man diese Daten standardisiert im laufenden Dokumentationsprozess adaptieren könnte. In einem zweiten Schritt wurde das Informationsmodell mit den tatsächlich vorliegenden Daten aus der Datenbank verfeinert. Einen Ausschnitt daraus zeigt Abbildung 2.

Ausschnitt aus dem Informationsmodell „Schmerz“
Datenadaptierung
Konkret hat sich gezeigt, dass vor allem edukative Maßnahmen im Schmerzmanagement und der Bereich der Erfassung der Schmerzbiografie angepasst werden sollten.
Auch im digitalen Pflegedokumentationssystem NCaSol wurden per Konfiguration einige Adaptierungen vorgenommen, sodass die Pflege in der Dokumentation des Schmerzmanagements besser unterstützt werden kann. So wurden das Thema Schmerz im Basisassessment optimiert, die Beschreibungsmöglichkeiten im Schmerzprotokoll angepasst, Pflegemaßnahmen zum Thema Schmerz gebündelt und nach einer Erfassung eines Schmerzprotokolls eine Abfrage zur möglichen Dokumentation der dazugehörigen Pflegeintervention eingebaut. Diese Umsetzungen wurden von den ProjektteilnehmerInnen der Pilotstation getestet und evaluiert.
Nach einer Schulung der MitarbeiterInnen auf der Pilotstation konnten die Adaptierungen für die Dokumentation in den Regelbetrieb übernommen werden. Phase 3 war somit abgeschlossen.
Ausblick
In Phase 4 wird sich dann zeigen, wie die Qualität der Daten für die Analysen wirklich ist. Dazu wird ein Datenqualitätskonzept entwickelt. Auch hierfür spielt das bereits erstellte Informationsmodell eine wichtige Rolle. Spannend werden dann die ersten Modellierungen für die Analysen und wie sich die gesamte Datenweiterverarbeitung organisieren lässt. Phase 4 und der Projektabschluss folgen dann in einem weiteren Blogbeitrag.